
Der Begriff Predicitive Policing erschließt sich am besten, wenn man ihn als Wort-Kompositum aus Predicitve Analytics und Policing versteht und ihn nicht aus der direkten Übersetzung ableitet wie z.B. bei Wikipedia mit „Vorhersagender Polzeiarbeit„. Die Polizeiarbeit besteht nämlich genau darin, dass mit Hilfe prädiktiver Analysemodelle (der Predictive Analytics) auf Basis von Fällen aus der Vergangenheit die Wahrscheinlichkeit von Verbrechen für die Zukunft vorhergesagt werden, um die Einsatzarbeit (Policing) entsprechend zu optimieren.
Hintergrund
Predicitve Policing folgt der Auffassung, dass (sich wiederholende) Kriminaldelikte einem Muster folgen und dass dieses Muster (Wer, Wen, Wann, Wo und Warum) anhand statistischer Daten beschrieben und analysiert werden kann. Ein Verbrechen, so willkürlich es auch aussehen mag, steht immer in einem Gesamtkontext. Vor allem (Big) Data kann dabei unterstützen, diesen Kontext besser (statistisch) zu erkennen und zu verstehen. Mithilfe entsprechender Modelle kann dann mit einer bestimmten Wahrscheinlichkeit ein weiteres Verbrechen (bzw. dessen Ort, Art, Opfertyp, Zeitpunkt usw.) vorhergesagt werden (vgl. W. L. Perry & Co. in Predicitve Policing, Rand 2013).
Eine interessante Unterscheidung zwischen Vorhersage und Prognose machen übrigens die Seismographen. N. Silver bezeichnet in seinem Buch „Berechnung der Zukunft“ eine Prediction als den Versuch, für ein zukünftiges Geschehen (Erdbeben) einen konkreten Zeitpunkt (und Ort) vorherzusagen. Ein Forecast dagegen bezieht sich auf Vorhersagen für einen längeren Zeitraum. Statistisch gesehen ist das Modell der genauen Orts- und Zeitbestimmung (Prediction) immer einer höheren Fehlerquote ausgesetzt.
Predictive Analytics und die Bedeutung von Daten
Predictive Analytics dient dazu, mithilfe von (möglichst vielen) Daten und statistischen Algorithmen das Eintreffen zukünftiger Ereignisse auf der Grundlage historischer Geschehnisse zu prognostizieren. Über Machine Learning lässt sich die Vorhersagequalität der Analyse stetig verbessern.
Dabei spielen grundsätzlich alle Daten eine Rolle. Und darin besteht auch die eigentliche Herausforderung: Genau die Variablen für ein prädiktives Modell zu finden, die für das Eintreffen eines bestimmten Ereignisses relevant sind. Dabei gibt es Daten, die
- direkt mit den (vergangenen) Ereignissen zu tun haben oder
- indirekt damit in Verbindung stehen.
Man kann auch sagen, dass es sich unter Punkt 1 um die offensichtlichen Merkmale zur Beschreibung eines Ereignisses handelt und unter Punkt 2 um die versteckten Merkmale.
Ein Beispiel: Es soll die zukünftige Kursentwicklung eines an der Börse notierten Unternehmens vorausgesagt werden.
- Zu Daten der Gruppe 1 zählen etwa der Kursverlauf selbst, die Börsenperformance gesamt, Veröffentlichungen, Ad-Hoc-Nachrichten zu Umsatz und Ertrag, usw.
- Zu Daten der Gruppe 2 gehören potenzielle Einflussfaktoren des Kurses oder des Unternehmens. Das können die unterschiedlichsten Informationen sein (z.B. Zulieferketten, Digitalisierungsrate, Altersstruktur, Frauenanteil, Hobbys der Manager usw.). Diese Parameter sind häufig (zunächst) nicht offensichtlich.
In Zeiten von Big Data wächst die Bedeutung der indirekten Daten – war doch in der Vergangenheit entweder der Zugang zu diesen Daten nicht möglich oder die Daten lagen nicht vor.
Predicitve Policing und die Rolle der Geodaten
Ein Ereignis findet oftmals nicht nur zu einer bestimmten Zeit, sondern auch an einem bestimmten Ort statt. Bei Verbrechen können das z.B. Einbrüche oder Gewaltdelikte sein (vgl. Einbruchsradar Köln und Leverkusen)
Ort und Zeitpunkt selbst können als direkte Parameter analysiert werden, um so über geostatistische Analysen z.B. Hot-Spots zu identifizieren (vgl. Abbildung, Quelle)
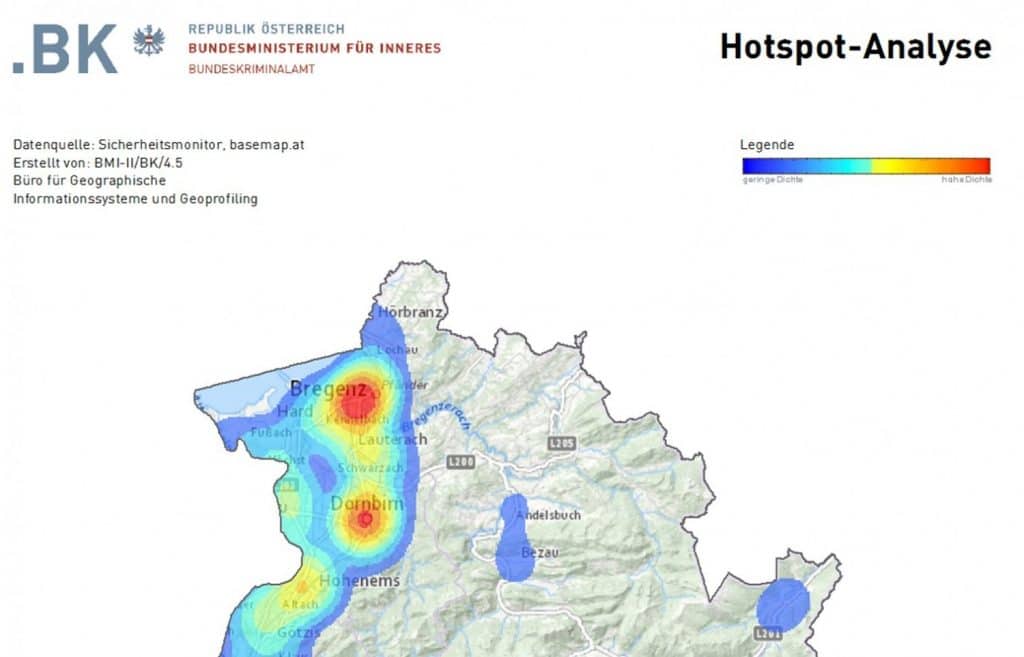
Das Ereignis selbst ist hier ein Geodatum. Und alle Geodaten haben wiederum den Raum als gemeinsamen Kontext, d.h. die Daten können über raumrelevante Parameter (z.B. Entfernung in Metern und Minuten) in ein Verhältnis zueinander gebracht werden.
Das spielt für die indirekten bzw. nicht-offensichtlichen Daten eine entscheidende Rolle. Ein Verbrechen mit Ortsbezug kann sofort mit allen weiteren verfügbaren Geodaten ins Verhältnis gesetzt und entsprechend analysiert werden. Und da in Zeiten von Big Data der Raum sein digitales Abbild in Geodaten erfährt, ist die Anzahl der verfügbaren Geodaten nahezu unendlich.
Ein Beispiel: Wiederholt findet ein Verbrechen in einer Stadtvilla statt. Nun spielen im ersten Schritt neben Ort- und den Zeitpunkten alle Daten wie z.B. Gebäudeinformationen, Garten, Straßentyp, Sozio-Demographie der Bewohner und Anwohner, das Viertel, KFZ-Daten (KBA), infrastrukturelle Anbindungen und Frequenzen eine Rolle. Ggf. aber auch Spielplatz, öffentliche Einrichtungen, Restaurants inkl. Öffnungszeiten und deren wiederum deren Frequenz usw. usw. Erst die Analysen werden die Zusammenhänge der Daten erkennen und eine Projektion in die Zukunft erlauben. Welche Variable dabei entscheidend zum Vorhersagemodell beiträgt, ist Bestandteil der Analyse. Es könnte die Tankstelle gewesen sein …
